|
|
 eMail Suche Impressum eMail Suche Impressum
|
Uni



Nächste Seite: 6. Begriffe und Abkürzungen Aufwärts: Performanztest Vorherige Seite: 4. Datenerfassung und Protokollierung Index
Unterabschnitte
Nächste Seite: 6. Begriffe und Abkürzungen Aufwärts: Performanztest Vorherige Seite: 4. Datenerfassung und Protokollierung Index
- 5.1 Fehlerraten
- 5.2 Aquisitionsfehler
- 5.3 Entscheidungsfehler
- 5.4 Abgleichfehler
- 5.5 DET-Kurven
- 5.6 Statistische Signifikanz und Testgröße
5. Auswertung von Fehlern
Die Performanz eines biometrischen Systems wird hauptsächlich
durch Fehlerraten charakterisiert. Es können an verschiedenen
Stellen im System fehler auftreten, diese möglichst genau zu
orten ist Aufgabe einer guten Auswertung.
5.1 Fehlerraten
Biometrische Merkmale unterliegen unterschiedlichen Schwankungen,
daher werden auf die erfassten Daten zwischen zwei verschiedenen
Zeitpunkten unterschiede Aufweisen. Daraus resultiert eine unvermeidliche
Fehlerquote eines jeden biometrischen Systems.
Möchte man nun die Sicherheit für ein Biometrisches System ermitteln, schätzt man diese Fehlerraten durch empirische Untersuchungen ab. Oft ist es der Fall, dass unabhängige Untersuchungen von den Fehlerraten stark von den Angaben der Herrsteller abweichen.
5.1.1 Vorgehen zum Erfassen der Fehlerraten
Es werden Referenzdaten von Testpersonen generiert und abgelegt, danach werden Daten der Testpersonen zur Authentifizierung erfasst. Die Ableiche mit den gespeicherten Referenzdaten werden bewertet und protokolliert. Über statistische Auswertungen ergeben sich dann verschiedene Arten von Fehlern, die im Folgenden beschrieben werden.
5.2 Aquisitionsfehler
Diese Fehlerart ist auf Fehlfunktion des Eingabegerätes oder auf
fehlende bzw- unzureichend ausgeprägte biometrische Merkmale
zurückzuführen.
5.2.1 Failure-To-Enrol-rate (FTE)
Mit der failure to enrol rate (FTE) wird der Prozentsatz der potentiellen Nutzer angegeben,
bei denen das Enrolment nicht erfolgreich durchgeführt werden konnte.
Als mögliche Ursachen sind die folgenden Aspekte zu berücksichtigen:
- Merkmal fehlt
- zu schwache Ausprägung des Merkmals
- Fehlendes oder unzureichendes technisches Verständnis (Person beherrscht den Gebrauch auch nach Einführung nicht)
- Systemprobleme z.B. Sensorqualität, Algorithmen
- Fehlende Akzeptanz des Verfahrens (z.B. aus gesundheitlichen Bedenken)
1#1
5.2.2 Failure-To-acquire-Rate (FTA)
Die Failure-To-acquire-Rate (FTA) ist das erwartete Verhältnis an
Transaktionen, die aufgrund von System-Fehlern bei der Aufnahme
von biometrischen Merkmalen fehlschlagen. Ursachen für diese Fehler
sind meist falsche Einstellungen wie falsche Entfernung
zu einem optischen Sensor.
5.3 Entscheidungsfehler
Diese Raten können Fehler bei der Datenaquisition enthalten
(z.B. durch unscharfe Bilder oder verschmutzte Scanner).
5.3.1 False-Accept-Rate (FAR)
Wird ein Benutzer vom System als jemand erkannt, der er eigentlich
nicht ist, spricht man von Falsch-Akzeptanz. In Sicherheitskritischen
Anwendungen darf diese Rate selbstverständlich nicht allzuhoch
ausfallen.
Diese Rate berechnet sich aus der Gesamtzahl fälschlicher Akzeptanzen (NFA), durch die Gesamtzahl unberechtigter Zutrittsversuche (NIA).
2#2
5.3.2 False-Reject-Rate (FRR)
Wird Benutzer vom System abgewiesen, obwohl er der vorgegebene Benutzer
ist oder obwohl er Zutritt zum System haben sollte, spricht man von
Falsch-Rückweisung. Diese Rate sollte nicht allzu gross sein, weil
sonst die Frustration der Benutzer steigt, wie auch die benötigte Zeit
bis ein erfolgreicher Versuch durchgeführt werden kann.
Diese Rate berechnet sich aus der Gesamtzahl fälschlicher Rüchweisungen (NFR) durch die Gesamtzahl berechtigter Zutrittsversuche (NEA).
3#3
5.3.3 Statistischer Zusammenhang
Die Erhöhung des Sicherheitslevels einer biometrischen Anwendung hat mehrere Konsequenzen. Zum einen sollte natürlich die False-Accept-Rate (FAR) fallen, also weniger Personen fälschlicher Weise als jemand anders erkannt werden. Aber damit steigt unweigerlich auch die False-Reject-Rate (FRR), denn durch das hohere Sicherheitslevel werden mit einer höheren Wahrscheinlichtkeit ``echte'' Versuche ablehnt.
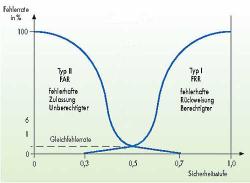 [4, Quelle: C'T: ``Im Fadenkreuz'']
[4, Quelle: C'T: ``Im Fadenkreuz''] |
5.4 Abgleichfehler
Diese Kategorie von Fehlerraten bezeichnen Fehler eines Algorithmus für einen einzelnen Vergleich zwischen aufgenommenem Merkmal (sample) und einem einzelnen gespeicherten Merkmal (enrolled template). Somit lassen sich Verwirrungen in Systemen verhindern, die mehrfache Authentifikation zulassen oder die mehrere Templates in ihrer Datenbank für eine Person gespeichert haben.
5.4.1 False-Match-Rate (FMR)
Wird auch als ``false positive'' bezeichnet.
Die FMR bezeichnet die Wahrscheinlichkeit, dass ein einzelnes Sample einem einzelnen, zufällig gewählten ``nicht-eigenenen'' Template zugeordnet wird.
5.4.2 False-Non-Match-Rate (FNMR)
Wird auch als ``false negativ'' bezeichnet.
Die FNMR bezeichnet die Wahrscheinlichkeit, dass von einem einzelnen Sample fälschlicherweise behauptet wird, dass es nicht auf das vom selben Benutzer abgegebene Template passt.
5.4.3 Unterschiede zu FAR/FRR
Abgleichfehler(FMR/FNMR) und Entscheidungsfehler (FAR/FRR) sind im allgemeinen verschiedene Raten. Abgleichfehler werden anhand der Anzahl an Vergleichen ermittelt, wohingegen Entscheidungsfehler auf der Basis von Transaktionen ermittelt werden. Entscheidungsfehler können somit auch von Aquisitionsfehler beeinflusst werden.
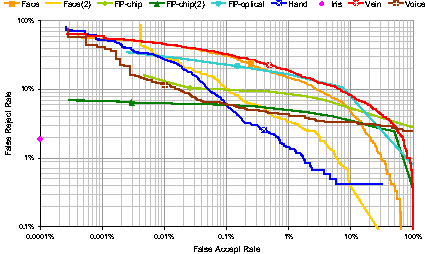
5.5 DET-Kurven
Detection error trade-off (DET)-Kurven dienen zu Visualiserung und
Gegenüberstellung von False-Accept-Rate (FAR) und False-Reject-Rate (FRR).
Hierbei werden die Achsen logarithmisch skaliert, um eine bessere Auflösung
der wichtigen Bereiche nahe dem Ursprung zu ermöglichen.
5.5.1 Eigenschaften einer DET-Kurve
Am folgenden Beispiel kann man so die Eigentschaften von FAR und FRR deutlich erkennen, und zwar:- Eine niedrige FRR hat eine hohe FAR zufolge. Um eine niedrige FRR zu gewährleisten muss das System genauere Merkmalsabgleiche durchführen, was dann oft zu einer höheren Abweisung von eigentlich berechtigten Personen führt.
- Je stärker sich ein Verfahren dem Ursprung der Kurve nähert, desto sicherer kann es im Vergleich zu einem weiter entfernten eingestuft werden. Theoretisch optimal wäre ein Verfahren das sich im Ursprung selbst befindet.
5.6 Statistische Signifikanz und Testgröße
Nach einer statistischen Auswertung eines Tests stellt sich die Frage:
wie genau sind die ermittelten Werte. Die Genauigkeit eines erzielten
Ergebnisses hängt hauptsächlich von der Grösse der Testdatensätze ab.
Nicht selten ist es nötig, dass man für die Bestätigung einer niedrigen FAR in hochsicheren Systemen mehrere tausend Testpersonen benötigt.
5.6.1 Menge an Testpersonen
Mit steigender Anzahl an Testpersonen sinkt die Varianz der Abschätzung und die erzielten Ergebnisse werden genauer, d.h. sie sind aussagekräftiger.Die Menge an benötigten Datensätzen (Anzahl Testpersonen) lässt sich über folgende Formel berechnen:
4#4
Dabei fliessen folgende Parameter in die Berechnung ein:
- 5#5 maximale Abweichung der realen von der geschätzten Fehlerwahrscheinlichkeit
- h bekannte Varianz
- Z Sicherheit der Abschätzung. Im Beispiel wird Z = 0,95% gefordert.
Diese nachfolgende Tabelle verdeutlicht, dass man für eine sichere Einschätzung einer niedrigen FAR eine beachtliche Menge an Testpersonen bräuchte.
Die entstehenden Raten dürfen keinesfalls überschätzt werden. In vielen Fällen werden nicht die volle Menge an Testpersonen einbezogen, sondern weniger Personen mit mehreren Merkmalen verwendet (z.B. rechtes UND linkes Auge bei einem Iris-System).
5.6.2 Rule of 3
Die Regel ``Rule of 3'' zielt auf die Fragestellung ``Welches ist die niedrigste Fehlerrate, die statistisch ermittelt werden kann anhand der Anzahl N an (unabhängig identisch verteilten) Vergleichen''. Dieser Wert ist die Fehlerrate p, für welche die Wahrscheinlichkeit von keinem Fehler in N Versuchen womöglich bei 5% liegt.7#7 für eine 95%iges Sicherheit
Bsp: ein Vergleich von 300 unabhängigen Merkmalen, die keinen Fehler verursachen, hat mit einer Sicherheit von 95% eine Fehlerrate von 1% oder weniger.
5.6.3 Rule of 30
Die ``rule of 30'' hilft bei der Abschätzung der Testgrösse:Um mit 90%iger Sicherheit sagen zu können, dass die tatsächliche Fehlerrate innerhalb von 8#830% von der bestimmten Fehlerrate abweicht, müssen mindestens 30 Fehler erfasst worden sein.
Sind unter einem Test mit 3000 unabhängigen, gültigen Versuchen 30 Fehlabweisungen, kann mit einer Sicherheit von 90% behauptet werden, dass die tatsächliche Fehlerrate zwischen 0.7% und 1.3% liegt.
Nächste Seite: 6. Begriffe und Abkürzungen Aufwärts: Performanztest Vorherige Seite: 4. Datenerfassung und Protokollierung Index
designed using WebCut - Copyright (c) 2001-2008 by Markus Sinner